SayNav is a novel planning framework, that leverages human knowledge from Large Language Models (LLMs) to dynamically generate step-by-step instructions for autonomous agents to complicated navigation tasks in unknown large-scale environments. It also enables efficient generalization of learning to navigate from simulation to real novel environments.

During the exploration of the new environment, the robot continuously builds the point cloud map and segments objects from images (semantic segmentation) for incrementally generating the semantic scene graph. SayNav uses this semantic scene graph, which represents objects with their geometric relationships, to ground LLMs for navigation.
Perception, semantic reasoning, and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments, such as searching and locating multiple specific objects in new houses. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. Current learning-based methods, with the most popular being deep reinforcement learning (DRL), require massive amounts of training for the agent to achieve reasonable performance even for simpler navigation tasks, such as finding a single object or reaching a single target point.
In our paper, we introduce SayNav, a new approach to leverage common-sense knowledge from Large Language Models (LLMs) for efficient generalization to complicated navigation tasks in unknown large-scale environments. Specifically, SayNav utilizes LLMs as a high-level planner to generate step-by-step instructions on the fly, for locating target objects in new environments during navigation. The LLM-generated plan is then executed by a pre-trained low-level planner that treats each planned step as a short distance point-goal navigation sub-task. This decomposition reduces the planning complexity of the navigation task – the subtasks planned by LLMs are simple enough for low-level planners to execute successfully.

SayNav example: The robot uses LLM-based planner to efficiently find one target object (laptop) in a new house.
To ensure feasible and effective planning in a dynamic manner, SayNav uses a novel grounding mechanism to LLMs, by incrementally sensing, building, and expanding a 3D scene graph during exploration. SayNav continuously senses the world using cameras and extracts scene graphs containing relevant information, such as 3D location of objects and their spatial relationships in the local region centered around the current position of the agent. The 3D scene graph is converted into a textual prompt to be fed to the LLMs. The LLM then plan next steps based on this information, such as inferring likely locations for the target object and prioritizing them. This plan also includes conditional statements and fallback options when any of the steps is unable to achieve the goal.
We tested SayNav using a photo-realistic benchmark dataset containing 132 unique ProcTHOR house environment, with different sizes (from 3 to 10 rooms), layouts, and furniture/object arrangements. The evaluation metric is time taken and success in searching and locating three different target objects in each house. Our results demonstrate that SayNav is capable of grounding LLMs to generate successful plans in a dynamic manner for this complex multi-object navigation task.
SayNav Framework

The overview of SayNav framework
SayNav includes three modules: (1) Incremental Scene Graph Generation, (2) High-Level LLM-based Dynamic Planner, and (3) Low-Level Planner.

The concept diagram for incremental scene graph generation
The Incremental Scene Graph Generation module accumulates observations received by the agent to build and expand a 3D scene graph, which encodes semantic entities (such as objects and furniture) from the areas the agent has explored. A 3D scene graph is a layered graph which represents spatial concepts (nodes) at multiple levels of abstraction with their relations (edges). This representation has recently emerged as a powerful high-level abstraction for 3D large-scale environments in robotics. Here we define four levels in the 3D scene graph: small objects, large objects, rooms, and house. Each spatial concept is associated with its 3D coordinate. The edges reveal the topological relationships among semantic concepts across different levels.
Search Plan prompt
System
Assume you are provided with a text-based description of a room in a house with objects and their 2D coordinates
Task: I am at a base location. Suggest me a step-wise high-level plan to achieve the goal below. Here are some rules:
1. I can only perform the actions- (navigate, (x, y)), (look, objects)
2. I can only localize objects around other objects and not room e.g. apple should be looked for on the table and not kitchen.
3. Provide the plan in a csv format. I have shown two examples below:
a) Goal = ‘Find a laptop’, Base Location = ‘LivingRoom’
– navigate; (3.4, 2.6); Go to table
– look; (laptop); Look for laptop near the table
b) Goal = ‘Find apple and bowl’, Base Location = ‘Kitchen’
– navigate; (3.4, 2.6); Go to DiningTable
– look; (apple, bowl); Look for apple and bowl near the DiningTable
– navigate; (8.32, 0.63); Go to CounterTop
– look; (apple, bowl); Look for apple and bowl near the CounterTop
4. Start the line with – and no numbers
5. Provide the plan as human would by e.g. based on contextual relationships
between objects
User
Room description
{room_graph}
Goal: {goal}
Base location: {base_location}
Room Identification Prompt
System
Identify the room based on the list of seen objects from the list below
– Kitchen
– LivingRoom
– Bathroom
– Bedroom
Output should be the room name as a single word without the –
User
{object_list}
The High-Level LLM-based Dynamic Planner continuously converts relevant information from the scene graph into text prompts to a pre-trained LLM, for dynamically generating short-term high-level plans. The LLM-based planner extends and updates the plan, when the previous plan fails or the task goal (finding three objects) is not achieved after the previous short-term plan executes. Note SayNav only requires a few examples via in-context learning for configuring LLMs to conduct high-level dynamic planning to complicated multi-object navigation tasks in new environments.
The Low-Level Planner converts each LLM-planned step into a series of control commands for execution. To integrate two planners, SayNav formulates each LLM-planned step as a short-distance point-goal navigation (POINTNAV) sub-task for the low-level planner. The target point for each sub-task, such as moving from the current position to the table in the current room, is assigned by the 3D coordinate of the object described in each planned step. Our low-level planner is trained from scratch (without pretraining) on only 7 × 105 simulation steps, using the DAGGER algorithm.
SayNav to Multi-Object Navigation
We use the recently introduced ProcTHOR framework, which is built on top of the AI2-THOR simulator, for our experiments. We build a dataset of 132 houses and select three objects for
each house to conduct new multi-object navigation task. We report two standard metrics that are used for evaluating navigation tasks: Success Rate (SR) and Success Weighted by Path Length (SPL). SR measures the percentage of cases where the agent is able to find all the three objects successfully, while SPL normalizes the success by ratio of the shortest path to actual path taken. In addition to these two metrics, we use the Kendall distance metric to measure the similarity between the object ordering obtained by the agent and that by the ground-truth. We use the Kendall Tau that converts this distance into a correlation coefficient, and report it over the successful episodes (all three targets are located).
To fully validate and verify the LLM-based planning capabilities in SayNav to multi-object navigation, we implemented two options for scene graph generation module and low-level planning module respectively for evaluation. The scene graph can be either generated using visual observations (VO) or ground truth (GT). Note that the GT option directly uses the ground truth object information, including 3D coordinates and geometric relationships among objects, to incrementally build the scene graph during exploration. This option avoids any association and computation ambiguity from processing on visual observations. We also use either our efficiently-trained agent (PNav) or an oracle planner (OrNav) as the low-level planner. For OrNav, we use an A* planner which has access to the reachable positions in the environment.
Given a target location, it can plan a shortest path from the agent’s current location to the target.
We also implemented a strong baseline method that uses the PNav agent to navigate along the shortest route to go through ground truth points of three objects. This baseline is to show the upper bound of performance from a learning-based agent to multi-object navigation, since the ground truth 3D positions of objects in the optimal order is provided to the agent.
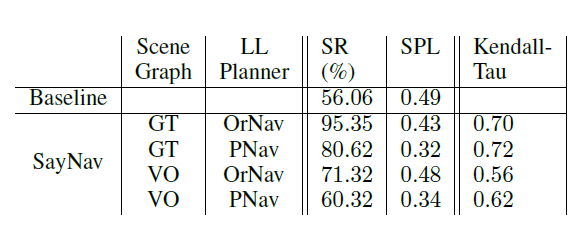
Results of SayNav on multi-object navigation task
Based on the experimental results, SR for the baseline method is only 56.06%, even after using ground-truth object locations in optimal order, which indicates the difficulty in successful execution of multiple (sequential) point-goal navigation sub-tasks, including cross-room movements. In comparison, SayNav, when building the scene graph using visual observations (VO) with either PNav or OrNav as the low-level planner, achieves a higher SR (60.32% and 71.32% respectively). This improvement highlights the superiority of SayNav in navigating in large-scale unknown environments.
Generalization to Real Environment
SayNav also enables efficient generalization from simulation to real environments. The same high-level LLM-based planning strategy can be learned through simulation, while the adaption is through low-level planning and control to accommodate differences between real and simulated environment.
Acknowledgement
This material is mainly based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001123C0089. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Projects Agency (DARPA). We would like to thank Rakesh “Teddy” Kumar, Ajay Divakaran, and Supun Samarasekera for their valuable feedback to this material. We also thank Tixiao Shan for experiments and demonstrations in the real world.
Authors
Abhinav Rajvanshi, Karan Sikka, Xiao Lin, Bhoram Lee, Han-Pang Chiu, Alvaro Velasquez
Published
September 15, 2023
Link to arXiv paper https://arxiv.org/abs/2309.04077


