Citation
Weng, F., Stolcke, A., & Cohen, M. (2000). Language modelling for multilingual speech translation. In The spoken language translator (pp. 250-264).
Introduction
As we saw in Chapter 14, the speech recognition problem can be formulated as the search for the best hypothesised word sequence given an input feature sequence. The search is based on probabilistic models trained on many utterances:
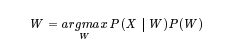
In the equation above, P (X j W) is called the acoustic model, and P (W) is called the language model (LM). In this chapter we present several techniques that were used to develop language models for the speech recognisers in the SLT system. The algorithms presented here deal with two main issues: the data-sparseness problem and the development of language models for multilingual recognisers.
As with acoustic modelling, sparse training data is one of the main problems in language modelling tasks. In both cases, we ideally want to have enough properly matched data to train models for all the necessary conditions. One may think that today’s technology, especially the Internet and the World Wide Web, lets us take for granted the availability of any amount of language modelling training data. Unfortunately, this is not entirely true, for three reasons:
- Style mismatch: Internet-derived data is usually written text, which does not have the same style as spoken material.
- Language mismatch: The available texts are not uniformly distributed with respect to different languages: there is plenty of data available for English, but not for other languages.
- Domain mismatch: The texts are not specifically organized for any speech recognition task.
Ignoring these mismatches can cause significant degradation to the performance of speech recognition systems. On the other hand, fully satisfying them may introduce data-sparseness problems.


