Machine learning
SRI has a rich history of R&D in machine learning, including enabling computer image sensors to sense, learn, and adapt to capture actionable information. CVT’s recent work has focused on deep learning and reinforcement learning for several applications, including Explainable Artificial Intelligence (XAI), Learning with Less Labels (LwLL), the Science of Artificial Intelligence and Learning for Open World Novelty (SAIL ON), Competency Aware Machine Learning (CAML), Lifelong Learning, Creative Artificial Intelligence, Approximate Computing, and Robust Artificial Intelligence.
Explainable AI, competency aware machine learning
CVT’s focus is on extending the state of the art in machine learning beyond supervised learning with large training datasets as well as human-intelligible explanations of machine learning techniques. In the DARPA XAI program, CVT developed new visual attention-based techniques to display where the machine learning-based question answering system has gone wrong and why. In the DARPA CAML program, SRI has developed new calibration techniques that help accurately predict actual performance by a machine learning algorithm in a new domain.
Lifelong learning, handling surprise, learning with less labels
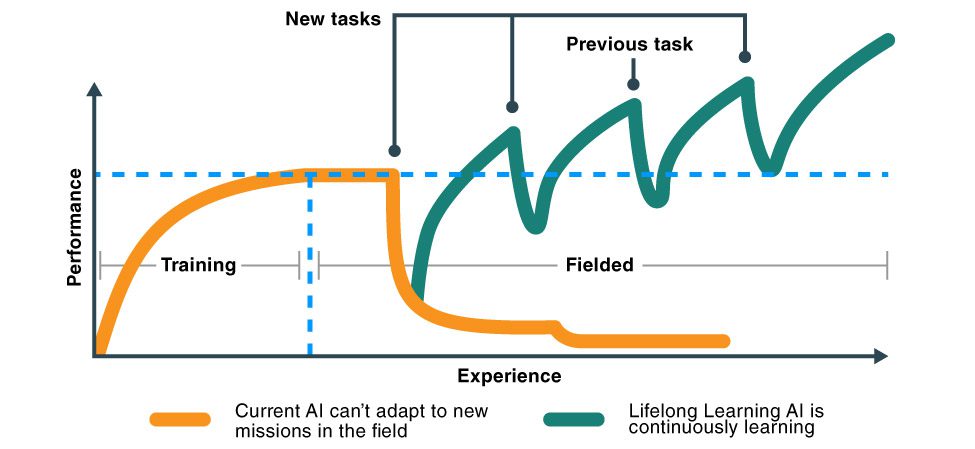
To get computers to learn from tasks they perform, CVT is developing lifelong learning algorithms and systems with machine learning capabilities to continuously learn over a stream of tasks (e.g., classification, autonomy tasks etc., over its lifetime) by leveraging the learned knowledge between related tasks to generalize to other tasks. To achieve the desired lifelong learning goals, CVT is working to solve the challenges of catastrophic forgetting, which is the problem of computers starting each task with no prior knowledge.
In the DARPA LwLL (Learning with Less Labels) and others programs, SRI has developed multiple techniques for learning from very little data. SRI has developed a Domain Adaptive Active Meta-Learning approach through active sampling of data to maximize information gain from each sample. We have also developed Hybrid Consistency Training to jointly leverage interpolation consistency, including interpolating hidden features, that imposes linear behavior locally and data augmentation consistency that learns robust embeddings against sample variations. We also use unlabeled examples to iteratively normalize features and adapt prototypes, as opposed to commonly used one-time update, for more reliable prototype-based transductive inference. Finally, we propose a modular adaptation method that selectively performs multiple state-of-the-art adaptation methods in sequence. As different downstream tasks may require different types of adaptation, our modular adaptation enables the dynamic configuration of the most suitable modules based on the downstream task. Our methods improve over the state of the art.

In the DARPA SAIL ON (Science of Artificial Intelligence and Learning for Open-world Novelty program), CVT developed predictive coding-based techniques for detection of novelties in new worlds. We have developed symbolic-based planning to detect novel situations in the environment. For the visual domain, we exploit the Open-AI CLIP neural model to generate embedding features. We use these embedding features to detect out distribution entities and visual novelties.
Approximate computing
Driven to reach ultra-low power embedded and edge-based computing solutions CVT developed our approximate computing BitNet technology. BitNet gives edge devices more computational range and battery longevity on the same COTs hardware.
Robust AI
Deep learning networks are vulnerable to so-called Trojan attacks in which the adversary poisons the training data with specially designed patterns that induce erratic behavior in the network when certain data, termed “triggers, “ are presented to it. CVT developed reverse engineering techniques to reconstruct possible trojan triggers, and studied the behavior of networks in response to such triggers so as to detect whether they have been the victims of a trojan attack. SRI’s techniques have been applied to Image Classification and Question answering and sentiment extraction using text. SRI’s techniques exploit logical constraints that impose compactness on the networks as well as sparsity of the attacks since they aim to go undetected. SRI’s techniques have advanced the state of the art in trojan detection and have achieved results that rank in the top three performers consistently.
On DARPA GARD (Guaranteeing AI Robustness Against Deception), CVT addressed the need for developing methods for building attack-agnostic robustness into machine learning (ML) architectures. Using an information-theoretic analysis framework, SRI’s GARD program developed multiple worst-case theoretical guarantees underlying different defensive approaches. Our metrics enable ranking of state-of-the-art (SOTA) Deep Neural Networks (DNNs) in terms of robustness and have paved the way towards safety standards for DNNs deployed in critical DoD applications.
- Researchers have demonstrated effective attacks on ML algorithms. On DARPA QED (Quantifying Ensemble Diversity for Robust Machine Learning), CVT researched developing effective defenses against such attacks which is essential if ML is to be used for defense, security, or health and safety applications. CVT developed an approach to dynamically change network DDNN eights and activations based on stochastic quantization (or generator) of a pre-trained neural network. We showed our moving ensemble approach improved protection of a network against attacks.
Recent work
-

SRI research aims to make generative AI more trustworthy
Researchers have developed a new framework that reduces generative AI hallucinations by up to 32%.
-

Artificial intelligence system continuously learns
SRI is developing a next-generation artificial intelligence system that applies continuous learning to become better at performing tasks.
-

Seeing the things that matter most
Using machine learning to enable computer image sensors to sense, learn and adapt to capture actionable information.
Recent publications
-
Unsupervised Domain Adaptation for Semantic Segmentation with Pseudo Label Self-Refinement
We propose an auxiliary pseudo-label refinement network (PRN) for online refining of the pseudo labels and also localizing the pixels whose predicted labels are likely to be noisy.
-
C-SFDA: A Curriculum Learning Aided Self-Training Framework for Efficient Source Free Domain Adaptation
We propose C-SFDA, a curriculum learning aided self-training framework for SFDA that adapts efficiently and reliably to changes across domains based on selective pseudo-labeling. Specifically, we employ a curriculum learning scheme to promote…
-
Night-Time GPS-Denied Navigation and Situational Understanding Using Vision-Enhanced Low-Light Imager
In this presentation, we describe and demonstrate a novel vision-enhanced low-light imager system to provide GPS-denied navigation and ML-based visual scene understanding capabilities for both day and night operations.
Featured publications
-
Hybrid Consistency Training with Prototype Adaptation for Few-Shot Learning
We introduce Hybrid Consistency Training to jointly leverage interpolation consistency, including interpolating hidden features, that imposes linear behavior locally and data augmentation consistency that learns robust embeddings against sample variations.
-
Generating and Evaluating Explanations of Attended and Error-Inducing Input Regions for VQA Models
Error maps can indicate when a correctly attended region may be processed incorrectly leading to an incorrect answer, and hence, improve users’ understanding of those cases.
-
Modular Adaptation for Cross-Domain Few-Shot Learning
While literature has demonstrated great successes via representation learning, in this work, we show that improvement of downstream tasks can also be achieved by appropriate designs of the adaptation process.
-
Confidence Calibration for Domain Generalization under Covariate Shift
We present novel calibration solutions via domain generalization. Our core idea is to leverage multiple calibration domains to reduce the effective distribution disparity between the target and calibration domains for improved calibration transfer without needing any data from the target domain.
-
Comprehension Based Question Answering Using Bloom’s Taxonomy
Our experiments focus on zero-shot question answering, using the taxonomy to provide proximal context that helps the model answer questions by being relevant to those questions.